Recipe Project #2 - Recommender System with Implicit Ratings
Business Question/Goal
- Can I build a recipe recommender system from information on the food52.com website. As a user of the recipes on this website, I wanted to build a recommender that does not rely solely on the recipe’s popularity based on the number of likes it garners.
Data Understanding
- The dataset used was obtained by scraping the food52 website - focusing primarily on recipes for dishes that were either “pork”, “chicken”, “beef” or “vegetarian” -based recipes. Using these search terms, a list of weblinks was generated and used to extract the following - recipe names, #likes, recipe ingredients, comments, from each recipe page. Since there were no explicit user/rating pairs provided for each recipe, implicit ratings were assigned based on sentiment analysis of user comments.
Data Preparation
-
A web scraper algorithm using BeautifulSoup was optimized with the search items “chicken”, “pork”, “beef”, or “vegetarian”. Each search term generated ~200 pages with about 20 unique recipe weblinks per page. Each list of web links was saved in a pickle file and used by a second program to scrape the data. The scraped data was saved in a mongo database.
-
The contents of the mongodb were extracted using this snippet in a jupyter notebook to generate a csv vile. Since most of the scraping was done using an AWS EC2 instance, this facilitated transport of the data back to a local machine for analysis.
Snapshot of captured Data
Data Summary
- Data was scraped from 9233 pages. For each of these pages, the recipe name, ingredients, and all user comments were captured. Unraveling the aggregated comments yielded 17733 unique users that provided a total of 52907 comments.
Deriving Implicit Ratings
- The food52.com recipe site did not have any explicit ratings data that can be gathered. Instead, I utilized the user comments left on the recipe pages and used NLTK’s VADER sentiment analysis method, which determines whether a string of text reflect a positive, negative, or neutral tone. The VADER analysis also returns a compound score which was used in the modeling. Turning on the implicit rating option for ALS is a simple switch in this parameter ALS(implicitPrefs=True).
Alternative Method for Implicit Ratings
Implicit ratings were also subsequently inferred from a different sentiment analysis approach. This will be discussed further in a different blog post.
Modeling Part 1
Unsupervised Clustering of recipe ingredients
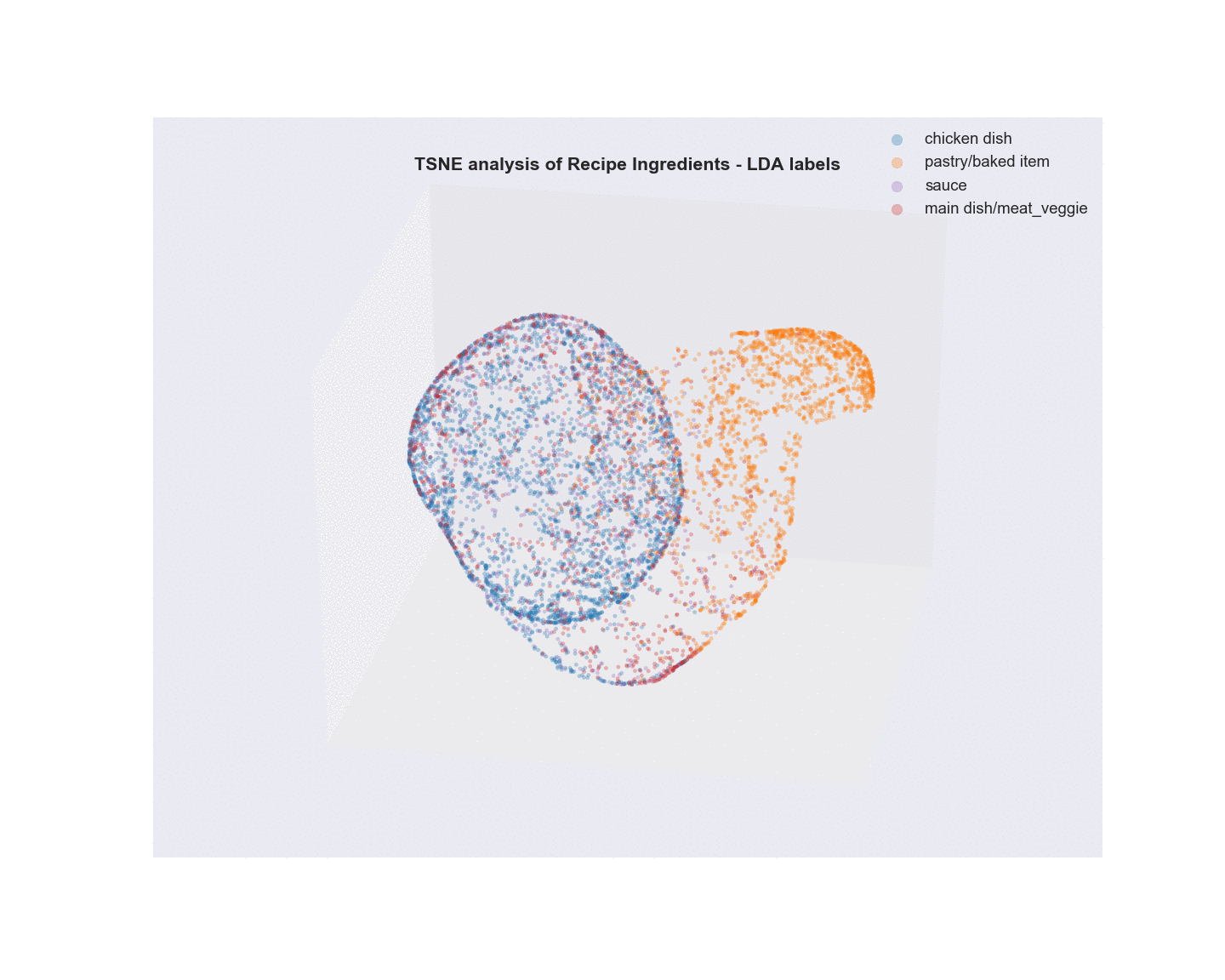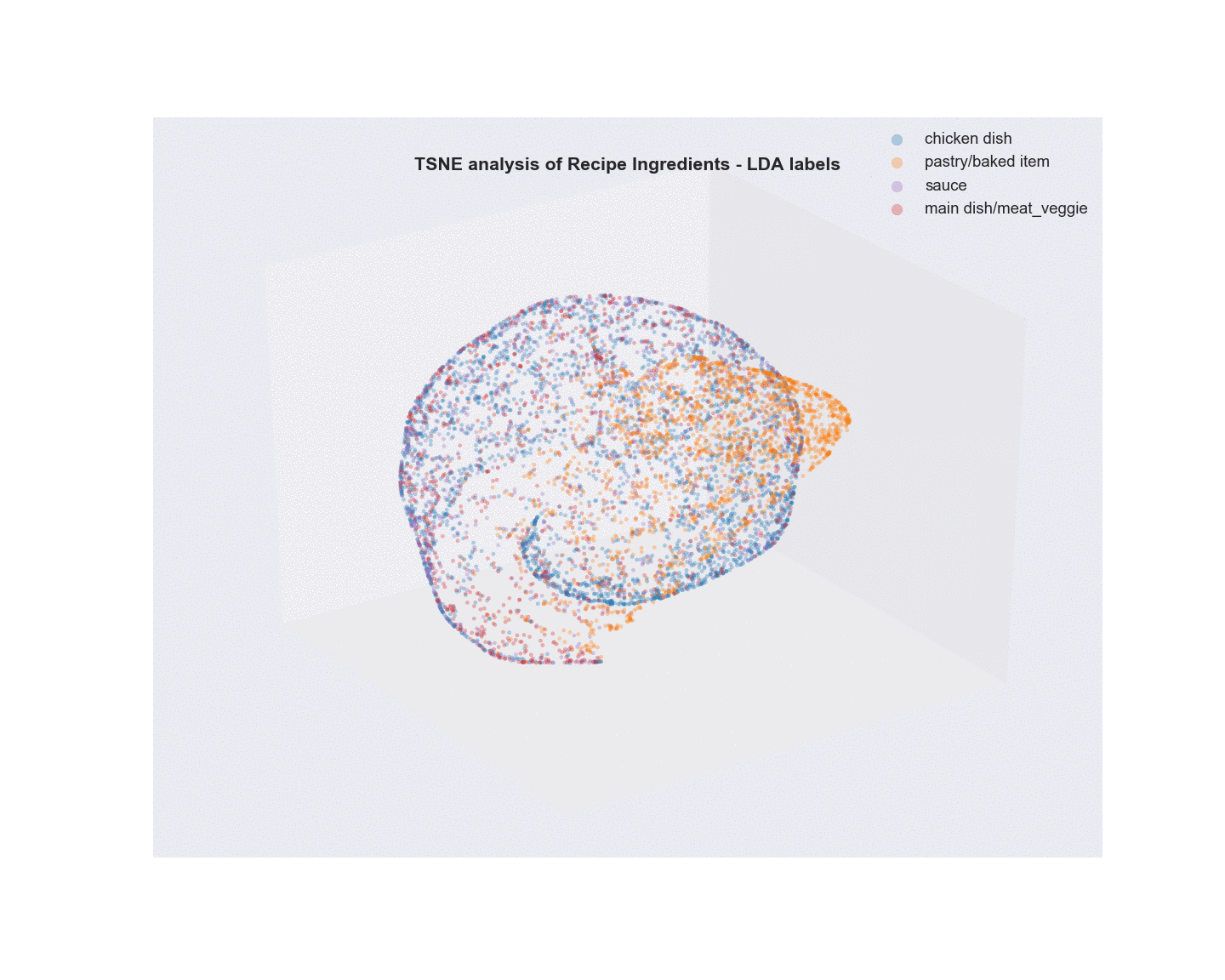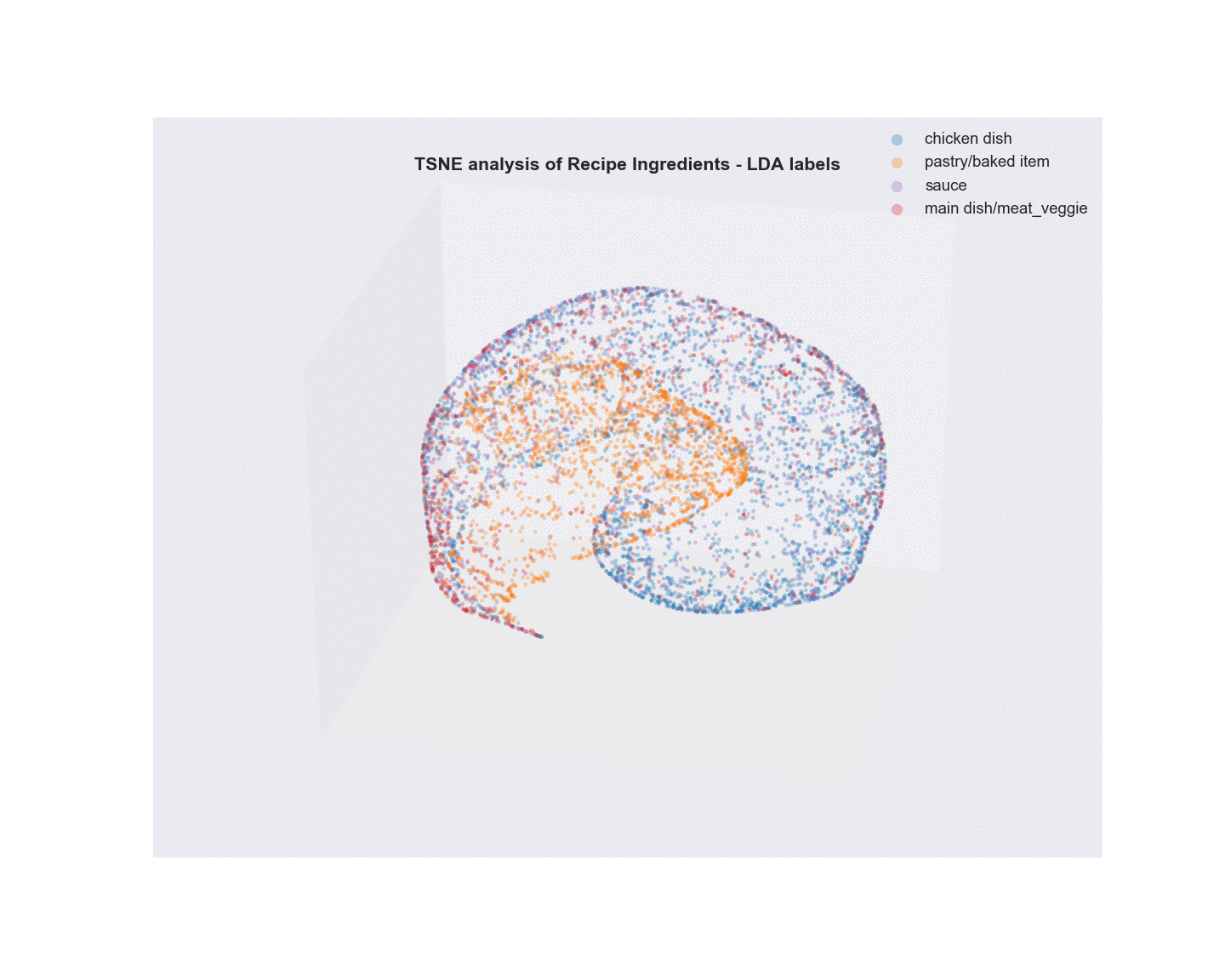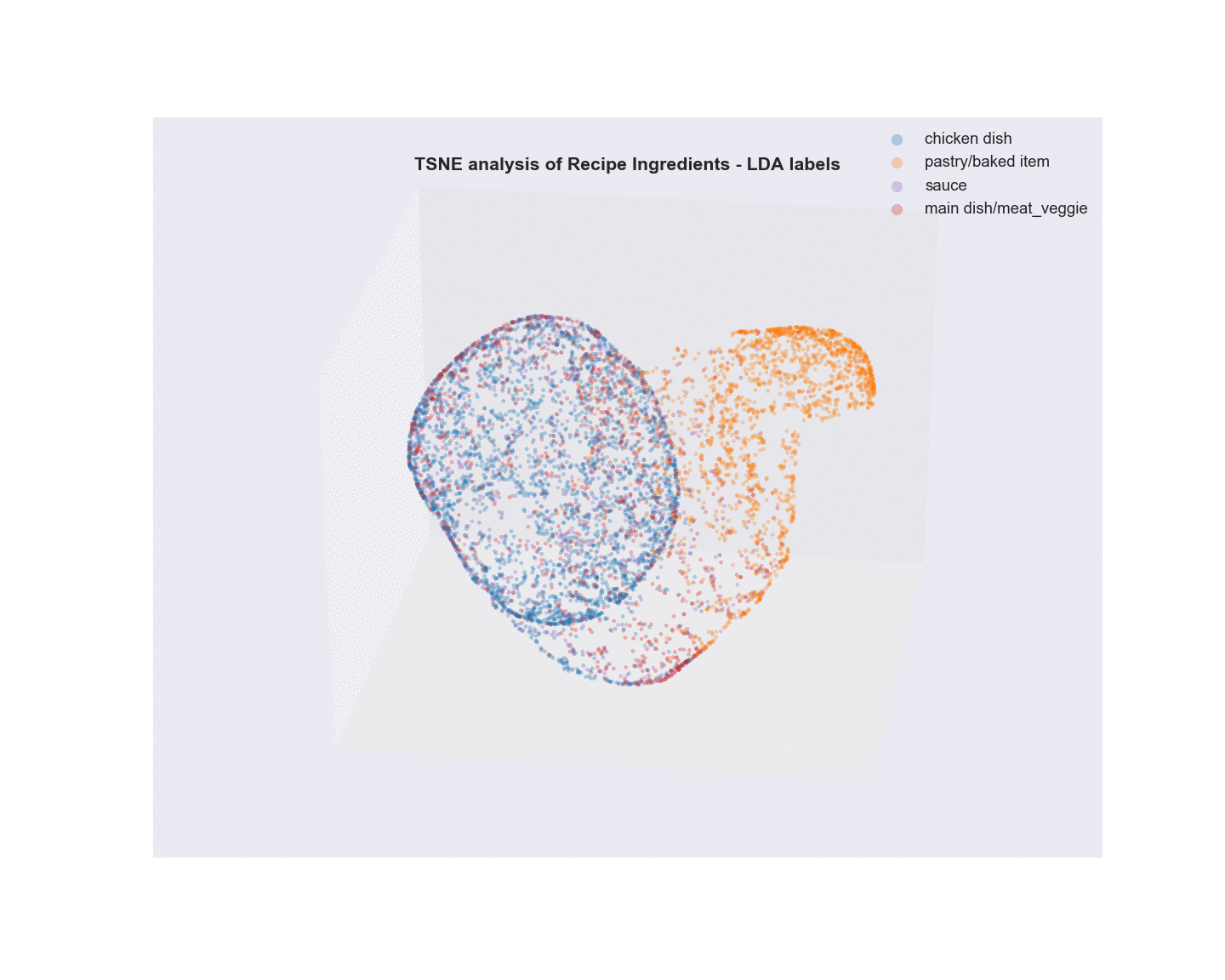
Algorithms Used - Non-negative Matrix Factorization (NMF) and Latent Dirichlet Allocation (LDA) of Recipe ingredients followed by t-SNE analysis for visualization.
- Unsupervised learning using NMF and LDA was used to analyze the text of recipe ingredients and to cluster similar recipes. Different number of clustering groups (n_components) to use was for both model and plotted. Subjectively, I determined that the ideal number of groups that show the best separation appear to be 6 with NMF and 4 with LDA. Considering the recipe data was scraped using four search terms, this is not unsurprising. The meat recipes appear to overlap quite a bit, possibly due to a lot of shared common ingredients(salt). In fact, as shown in the two wordcloud images, the most common words overall in the recipe text are terms that denote measures of ingredients. Once these and other common terms are added to the set of stopwords prior to text vectorization, the clustering becomes a little more apparent.
Word Cloud before and after removing measurement terms

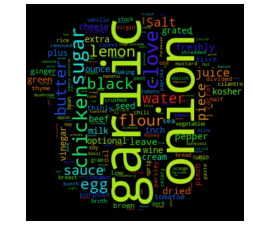
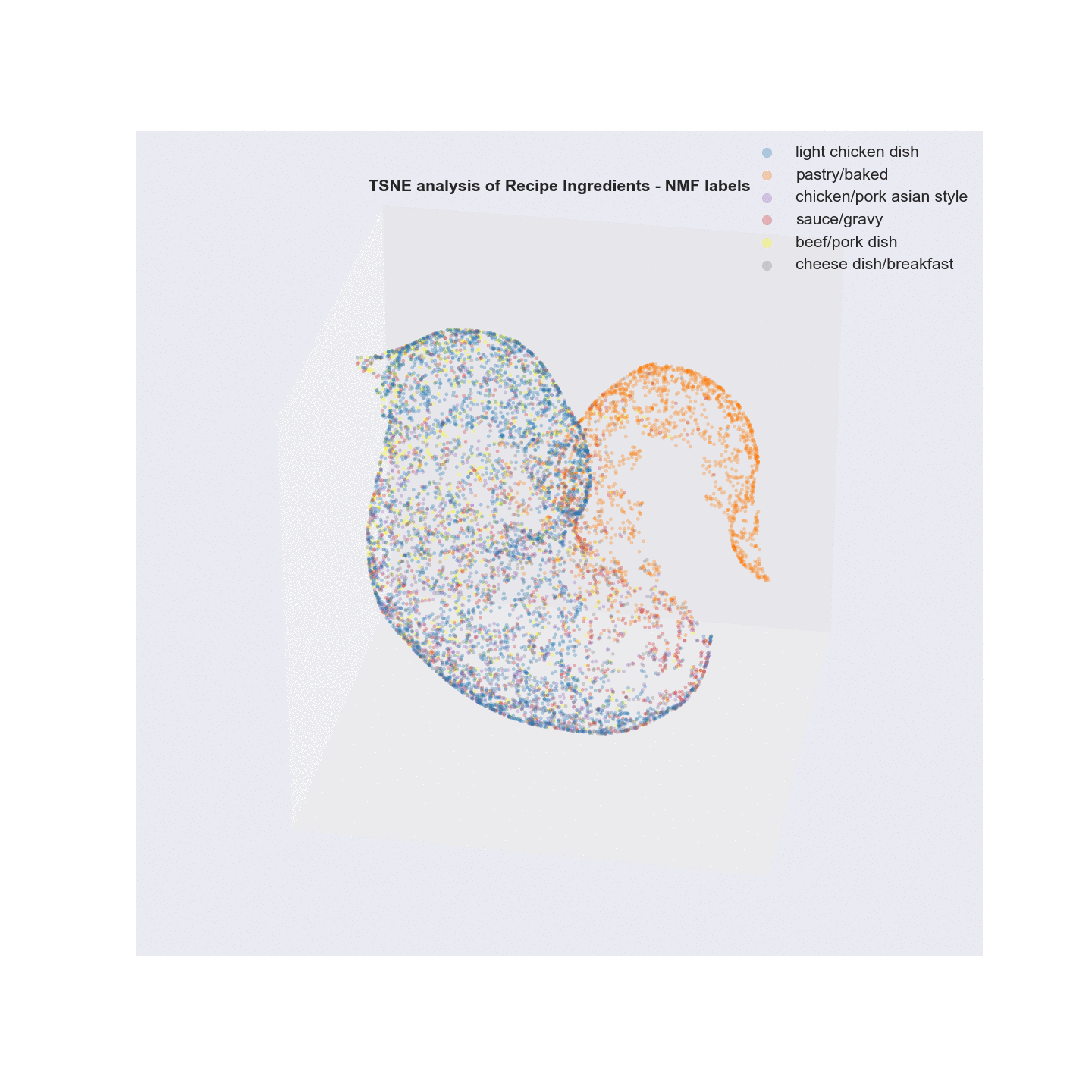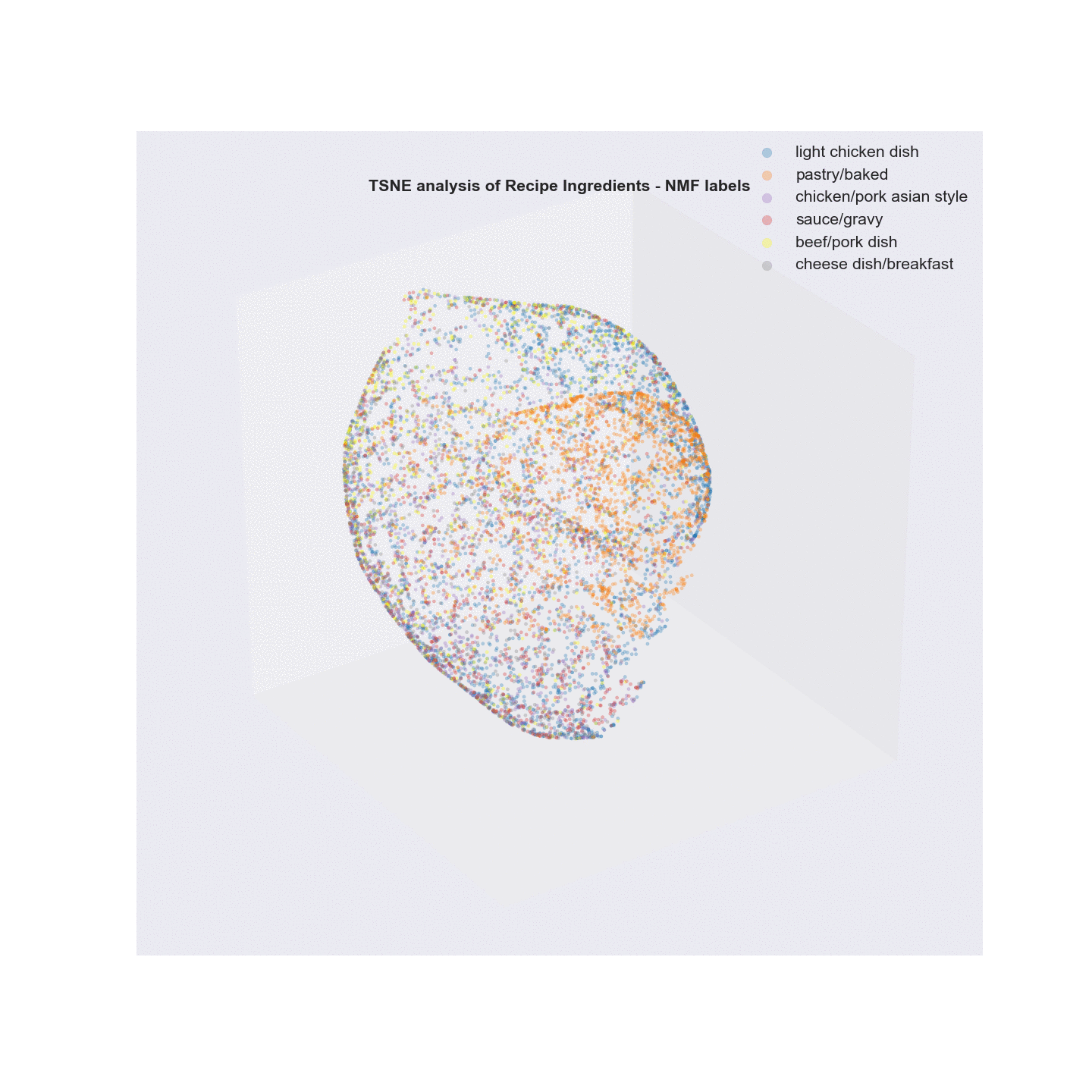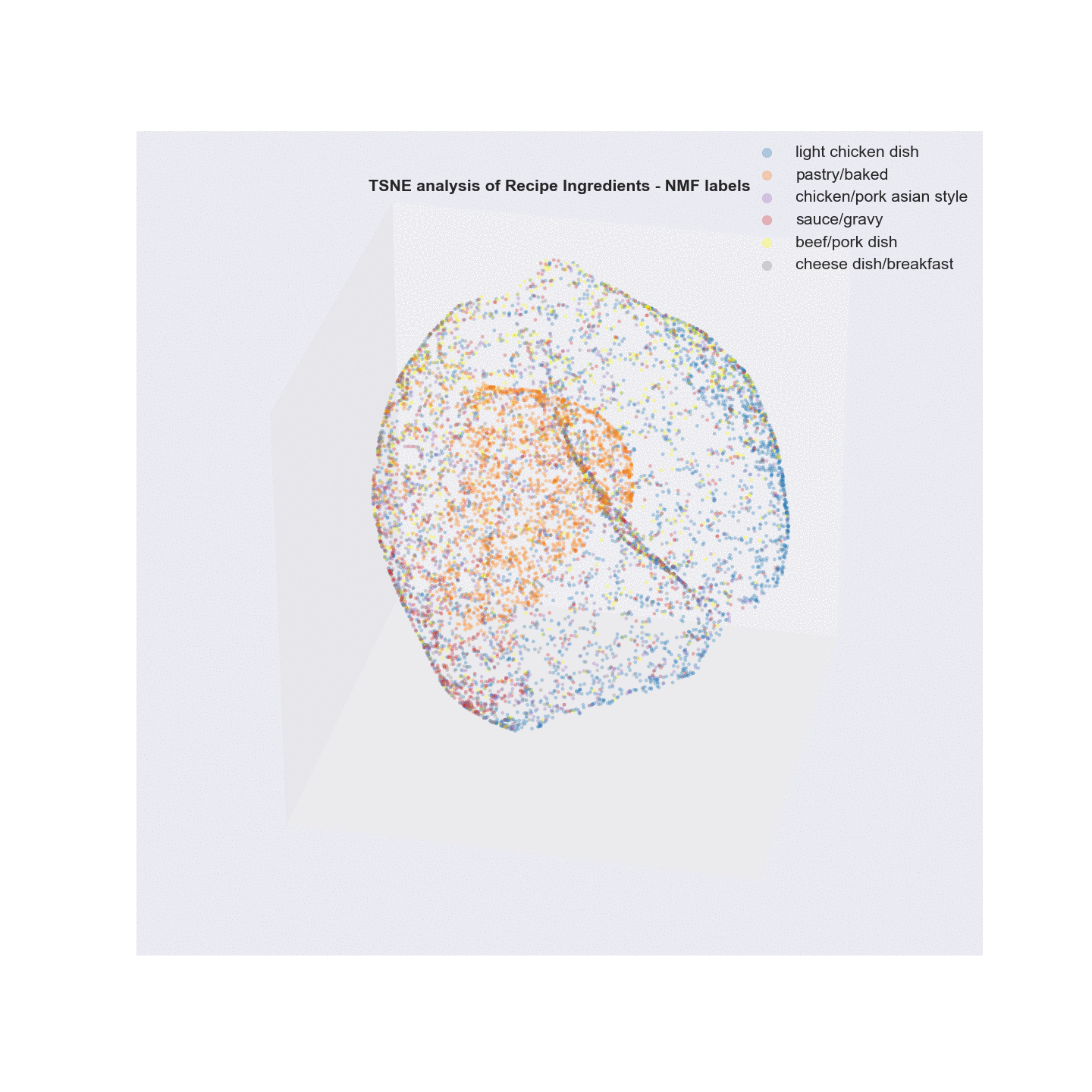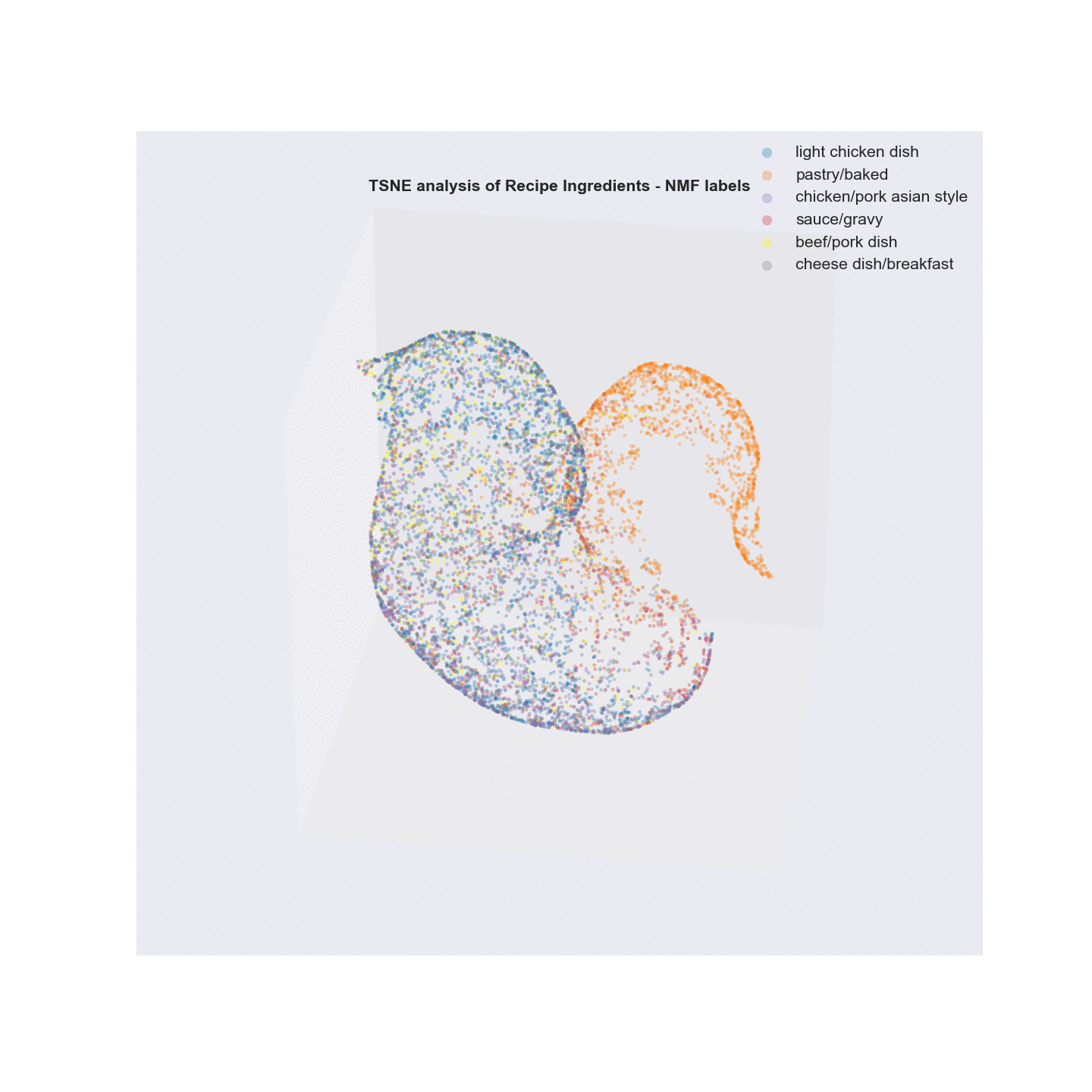
- Visualization/Evaluation - truncated SVD(singular value decomposition) combined with t-distributed stochastic neighbor embedding(TSNE) was used for dimensionality reduction of the vectorized recipe text matrices (TF, TFidf). x, y, and z coordinates (n_components=3) were extracted from the TSNE analysis and each coordinate set was given a label based on either the LDA or NMF analysis and plotted in a 3D scatter plot. The plots were labeled with summary terms of the top topics from each clustering analysis. Animating the 3D plots provides a glimpse on how well the clustering worked. For both LDA and NMF analyses, there was a clear grouping for baked items (top topics - flour, butter, sugar). The huge overlap in common ingredients aside from the type of meat in what I call “savory” dishes possibly points to why salt, garlic, and onion are the primary terms in the word cloud.
Using Non-negative Factorization (NMF) to group recipes aka Latent Semantic Analysis (LSA)
Latent Dirichlet Allocation (LDA)
Modeling Part 2
Collaborative Filtering
- Spark MLLib Alternating Least Squares - The recommendation system was built using Spark’s ALS model. The method of collaborative filtering aims to predict the rating of an item by a user based on the behavior of other users that “like” or highly rate the same or similar items. In short, the model takes into account the past actions (likes/ratings/purchases/web page views) of a particular user we’ll call UserA as well as the behavior of other users who have rated or liked the same or similar items. Recommendations are based on this second set of “similar” users’ inclination for items or products that UserA has not seen or rated.
Using the sentiment scores as the labels, the ALS model was set to infer implicit ratings (implicitPrefs=True).
Evaluation of the recommender model
- The user/recipe/implicit ratings matrix was split 70/30 for use as a training and test set. In the resulting ALS model, since I used ImplicitPrefs=True, the predicted scores I obtained from the test data set would not necessarily align with the compound scores that I used to derive the “intent” of each comment. For this reason, the root mean square error evaluation between the predicted and true score will not be an appropriate measure.
Instead, I utilized Rank Discounted Cumulative Gain to evaluate the predictions against the true scores. The true scores (reference) and the predicted output (hypothesis) are ranked and the algorithm maps each hypothesis score to the reference and returns a score. For more info, this repo contains the code I used. The paper that the author wrote is here
Grid Search Parameter Optimization
| Rank | Regularization | rankDCG Score |
|---|---|---|
| 1 | 0.1 | 0.563 |
| 1 | 0.5 | 0.543 |
| 1 | 1 | 0.499 |
| 2 | 0.1 | 0.439 |
| 2 | 0.5 | 0.513 |
| 2 | 1 | 0.510 |
| 5 | 0.1 | 0.432 |
| 5 | 0.5 | 0.552 |
| 5 | 1 | 0.517 |
| 10 | 0.1 | 0.581 |
| 10 | 0.5 | 0.502 |
| 10 | 1 | 0.415 |
| 50 | 0.1 | 0.471 |
| 50 | 0.5 | 0.528 |
| 50 | 1 | 0.593 |
Deployment
- The ultimate measure of a recommender’s effectiveness is to measure how well the users interact with the recommended output. Deploying the recommender to a subset of web visitors and to the website and analyzing the click-through rate (CTR) data for the recommendations is a good way to measure success. Ideally, the RS would be integrated into the website, which can provide existing users with a list of recipe recommendations i.e. recipes they have not rated/commented on but is aligned with what similar users have rated. Whether the user provides comments on any of the recommendation (positive or negative) can be used as a metric on the RS’s effectiveness. For new users, the cold start strategy can start with something simple. New visitors are presented with the most popular recipes. The number of likes is a metric that’s pervasive in the food52.com website and the most-liked items can be viewed as the “most popular”. Again, the feedback from the new user about these recipes can then be fed into the RS and recommendations/insights can then be updated.
Final Thoughts
-
Since I am not employed at food52.com, I can only propose an ideal deployment scenario that can be put into practice and then assessed and changed as new data comes in. I feel that this exercise illustrates that deriving implicit ratings to infer user intent can be done but an explicit ratings system may be more useful. The fact that this analysis attempts to determine user intent from comments that were left for a myriad of unknown reasons. The visitor may have been just asking a question about the recipe or providing thoughts on ingredient substitutions for example. This is possibly why some merchants (e.g. Amazon) provides a separate product question/answer forum which is distinct from the customer review. In that case, they can analyze both the explicit ratings and the implicit intent as well.
-
If I had access to the data stream at food52.com, one way to get better implicit ratings is to use the visitor’s IP address as a user id. One can then log which recipe pages each user visits and whether or not they give the recipe a star (like) or not. A simple scoring system might be like the following table.
| Viewed Page | Action Taken | Score |
|---|---|---|
| Yes | Did not press Like. No comment or negative comment | 1 |
| Yes | Did not press Like. Left positive comment | 2 |
| Yes | Pressed Like. | 3 |
| Yes | Pressed Like + Positive Comment | 4 |
Since there is a tendency for consumers to be “lazy” about giving feedback on web-based, I would predict that with this schema, the mean score would be closer to 3.
- I may revisit this project again to see if I can improve the recommender.