Motivation
One of the things that I thoroughly enjoy doing at home is cooking. There is something cathartic about the process, where you take a disparate collection of ingredients and create something that will hopefully provide both enjoyment as well as nourishment. Ergo, my bookshelf has quite a number of cookbooks that I consult constantly and has provided a good repertoire of dishes to prepare for either a meal for four or a spread for several guests.
Of course the internet has provided and continues to add content that offers an alternative to cookbooks. Any Google query for a particular dish returns an inordinate number of links to recipes for that dish. (query: ‘blueberry pancake recipes’. return: 5.1 million results) And, a different search parameter (‘recipe websites’), returns 4.5 million results. One must navigate through these results to find a recipe that suits one’s tastes and cooking style. After trial and error, I now just use the Allrecipe and food52 websites for my needs. There’s still a need to navigate these expansive websites and so I felt that a recommender system was a good exercise to try out. This post is about the Allrecipe.com work which relies on explicit rating data. I also built one that used implicit ratings and will discuss that in a second post.
Note Code and other relevant information can be found in this Github Repo. I only use the data I obtained from the site to do this particular data science project.
Recipe Project - Vegetarian Dish recommender
Business Question for this Exercise/Project
- Build a recipe recommender system (RS) from data scraped from the allrecipes.com website.
Data Understanding
- To build an RS using collaborative filtering, users, items(recipes), and the rating that each user gives for an item are required. The allrecipe.com star rating system ranges from 1-star(not-highly rated) to 5-star(highly rated). There is a huge amount of information that can be collected from this website and the initial goal was to collect as much user/recipe/ratings information from the site. However, for brevity, the project was streamlined into an RS for recipes that were returned by the term “vegetarian” on their site’s search engine.
Data Preparation
-
A web scraper algorithm was created to gather ~4000+ individual recipe weblinks from the allrecipe search page. Once the weblink list was collected, a second scraping program accessed each page to extract relevant information - recipe name, and unique user_names with their user ratings for that recipe. For recipes with a large number of ratings, the number of users/ratings collected was capped at 100, to facilitate the completion of a minimum viable product. For recipes that have not been rated by any user, a rating score of 0/None was assigned.
-
The data collected by the scraper program were dumped in mongod. Exploratory data analysis was performed in a Jupyter notebook where the mongod contents were transformed into a continuous table containing columns for user_id, recipe_id, and rating. Each user_id and recipe_id is an integer that corresponds to a unique user or recipe name. The pickled name:id dictionaries are in the data folder. The final dataset had ~162K unique ratings with ~4000 recipe_id’s and ~87.8K user_id’s.
Snapshot of captured Data
- Total count per rating category - This table shows the overabundance of 5-star ratings compared to all others.
| Rating | Counts |
|---|---|
| 5 | 106922 |
| 4 | 39092 |
| 3 | 10151 |
| 2 | 3731 |
| 1 | 2751 |
| 0 | 24 |
Modeling
- Algorithm Used - Collaborative Filtering
- Spark MLLib Alternating Least Squares (ALS) - The method used to extract user/item relationships was the alternating least squares method from the Spark MLLib library. 87786 unique users provided ratings (1-5) for ~3.9K unique recipes. The methodology used here is fairly similar to another recipe project I completed. The difference lies in the type of ratings that I used in each, implicit ratings in the other project and explicit ratings with the allrecipe dataset presented here.
- Cold Start Approach - As a simple approach to the problem of recipes and users that do not appear in the training dataset for the model, I filled in a “predicted” value based on the following:
- overall average = mean of all training set ratings
- user bias = user’s average rating - overall average
- item bias = recipe’s average rating - overall average
- Implementation Adding this to the ALS predictions, the final adjusted predictions then become:
- final pred = ALS Prediction + user bias + item bias
- new items/users i.e. not seen by training set
- final pred = overall average + user bias + item bias
- A Note about bias implementation There are a number of ways to deal with the cold-start problem. For instance, if the problem is due to a new/unseen user, a popularity based recommendation can be a starting point i.e. suggest the most popular items, in this case recipes to the new user. For new items, the one I chose to implement could work initially. The method I employed was done for brevity and not necessarily to make the model’s performance better or have higher accuracy. Of course, a recommender system’s greatest asset is that it is constantly evolving with more user and item data.
Optimization and Validation
- The data was split 80/20 for training and testing purposes. Using alternating least squares (ALS) to train the larger dataset, the resulting model was used to derive predictions on the test data set. Bias correction was added to the ALS derived score to get a final predicted value. This was compared against the true predictions (true score-predicted rmse_score)to derive the root mean squared error (RMSE). The bias correction that was employed was successful in minimizing the RMSE for the test set. However, plotting the predictions against the true ratings, one can see that the model performs poorly with the low-rated recipes(1-2 stars).
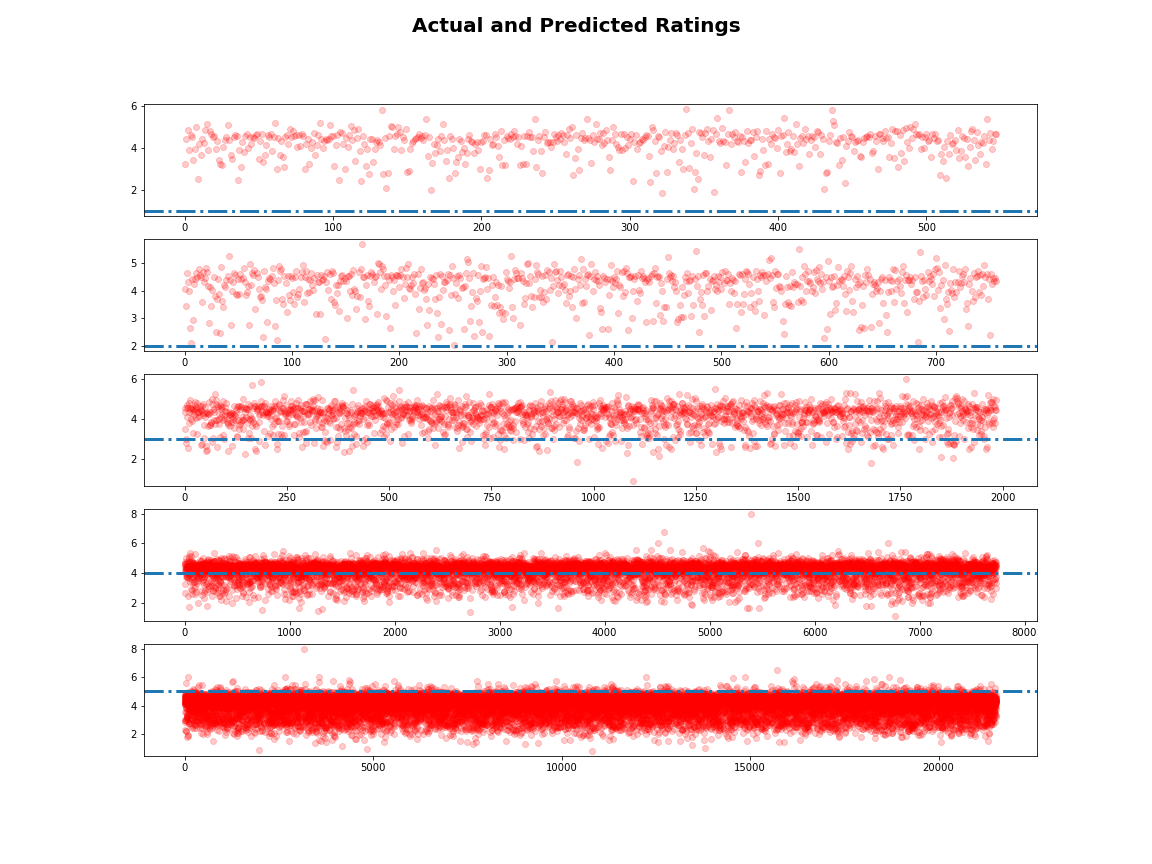 This is an expectation with recommendation system algorithms i.e. the predictions will generally gravitate towards the mean, which in this case is between 4 and 5 since 90% of the recipe ratings in this dataset were either a 4 or 5, with the majority of it being the latter. The skewed ratings data is something that is commonly encountered when users are asked to rate items in a web page. The majority of users that engage in providing feedback are ones that provide the most positive response, hence the dearth of low rated recipes.
This is an expectation with recommendation system algorithms i.e. the predictions will generally gravitate towards the mean, which in this case is between 4 and 5 since 90% of the recipe ratings in this dataset were either a 4 or 5, with the majority of it being the latter. The skewed ratings data is something that is commonly encountered when users are asked to rate items in a web page. The majority of users that engage in providing feedback are ones that provide the most positive response, hence the dearth of low rated recipes.
Deployment
- As I was optimizing my web scraper, it came to my attention that allrecipes.com has put in a recipe recommender on their splash page. These are most likely based on popularity i.e. recipes that have high number of top ratings, which for some recipes on this website must number in a few thousands. So, it is easy to conceive that for a new or unregistered visitor to their site (new user), they have a number of items to recommend based on these highly rated recipes. I am not exactly sure if this is the algorithm used on the site but it is one that I would implement. Once these new users have rated a few items, they can then be incorporated into the data set and a set of recommendations based on similar users/recipe combinations can be derived. For newly added recipes, an alternative implementation can be the following. Using the text of the recipe ingredients to derive similarities with other recipes in the dataset (see clustering of my food52 recipe project), the new recipe can be recommended along with items that cluster with it.